There is a long list of benefits to running applications on Kubernetes, but complexity of the application lifecycle can come along with this added layer. Upgrading software is one of the most complicated and error-prone operations. Whether you’re talking about a monolith living on a single server, or a distributed microservices application spread out across multiple clusters, almost every scenario has its own set of obstacles.
For software living on Kubernetes, one of those challenges is a timing one: When can I upgrade my software safely? Here’s an example: You have to wait until all units of work are completed in your application to safely and cleanly upgrade your software. A (very) manual way to solve this is to monitor and wait until your condition is met, and then start your upgrade. But we want to move away from manual processes and focus on automation, especially if we are releasing our software from a Continuous Delivery (CD) pipeline.
Sample/demo Kubernetes application and Helm chart can be found on my GitHub repo.
Helm hooks
If you are managing your Kubernetes applications with Helm, you already have a headstart on a really elegant solution to this problem. Helm allows you to control the lifecycle of its operations through the use of chart hooks. There is a list of what’s available, but for our purposes we’re looking for the pre-upgrade hook.
How do you create a hook?
A hook is going to be just like any other Helm template, but it will be something you will want to be created during the set part of the lifecycle for the hook. In the case of a pre-upgrade operation that you want to run prior to the upgrade (like in our scenario), that would most likely be a job. Here is what a hook could look like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
apiVersion: batch/v1
kind: Job
metadata:
name: pre-upgrade
annotations:
"helm.sh/hook": pre-upgrade
spec:
template:
metadata:
name: pre-upgrade
spec:
restartPolicy: {{ .Values.preUpgrade.restartPolicy }}
containers:
- name: pre-upgrade
image: "{{ .Values.preUpgrade.image.repository }}:{{ .Values.imageTag }}"
command: ["./pre-upgrade.sh", "{{ .Values.service.name }}"]
The part that makes this an actual hook (instead of just a normal Helm template to be bundled and shipped with the manifest) is the helm.sh/hook annotation. This should be set to the hook lifecycle event that you want it to run as (in our case, pre-upgrade).
What should the pre-upgrade hook do?
Above we see the Helm template that is used for the hook, but the actual upgrade synchronization is going to be happening in the container that is running in the hook. In my sample application, I have a pre-upgrade.sh shell script that is the core logic of determining if/when we can move forward with the upgrade. Once this pod completes, then the release upgrade will happen. Here is an example of some logic that I’m using in the sample application:
1
2
3
4
5
6
7
8
9
10
11
12
13
while true; do
IS_UPGRADEABLE=$(curl -s "${APP_SVC}/upgradeable" |
python3 -c 'import sys, json; print(json.load(sys.stdin)["isUpgradeable"])' |
tr '[:upper:]' '[:lower:]')
echo "$(date) - Is upgradeable: $IS_UPGRADEABLE"
if [[ "$IS_UPGRADEABLE" == "true" ]]; then
echo "$(date) - Cluster is upgradeable"
break
fi
sleep 10
done
All I’m doing in my pre-upgrade hook implementation is polling an application API endpoint (/upgradeable) to determine if the application can be cleanly upgraded. If the application says it isn’t ready to be upgraded, then we will just loop until it is. And when it is upgradeable, the pod will complete and the upgrade will continue. Here’s a good visualization of the process:
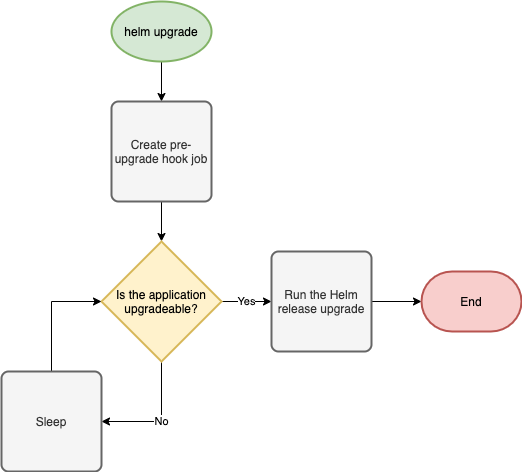
But why not…
…increase the graceful termination period?
This is a good solution if your code handles SIGTERM (this is the signal that Kubernetes will send to the pods for termination) and if there is a relatively short amount of time that the pod will need to be able to cleanly terminate. But in many cases, we might need more complex logic (like polling an API endpoint for when we can upgrade) that will determine when we can, instead of just arbitrarily raising the static grace period. We might be able to upgrade now, in 5 seconds, in 5 minutes, or 5 hours. We need our pre-upgrade hook to give us the go-ahead.
…use a PreStop container hook?
Much like the graceful termination period, this would be a good solution if we wanted to separate the cleanup/shutdown logic in a separate process (container), but it wouldn’t give us the time flexibility we may need. This is a solution for what do we need to do for a shutdown, not necessarily when can we shutdown.
Considerations
What is your upgrade-ready logic?
My sample application publishes an API route that can give us the information that the hook needs to know. But this could be different with other scenarios. It could use queue length, a database query, or… you name it. How would you manually determine that you can upgrade? Hopefully that logic can be represented in code and plugged into the pre-upgrade hook.
helm upgrade timeout
If your upgrade synchronization is a short amount of time (e.g. a couple of minutes), then you probably wouldn’t ever have to think about Helm timing out. But keep in mind that helm upgrade has a default timeout of 5 minutes. Set this to a more appropriate value for your upgrade and application requirements. Maybe your upgrade could take up to an hour?
helm upgrade --install
It’s common to use the --install flag for helm upgrade so you can have a single command to either upgrade your release or install it if it doesn’t exist. In the event that the installation operation happens, your pre-upgrade hook will not run. This is probably what you want. But if you have operations that need to happen prior to an install, then you’d want to implement a pre-install hook.